




Hi and welcome
This is the third post on my series of blog posts on the pandas library. if you're new to the pandas library or need a re-fresher on it, then i suggest you go through the previous post .
In this post, i will be treating the following
- How to import csv files
- How to drop columns/rows
- How to work with string methods
Importing csv files
So far we have being working with data generated with python and numpy, however in the real situation, data scientist hardly work with those kind of data. The ideal situation is to import data from different file types, including databases. In this section we shall be considering how to import Comma Separated Values(csv) .
I will be working with a file saved in the same directly as the python file i'm working with. You can also import from other directories using absolute paths and other method of relative paths.
Now, create a file with the following content and save it as records.csv
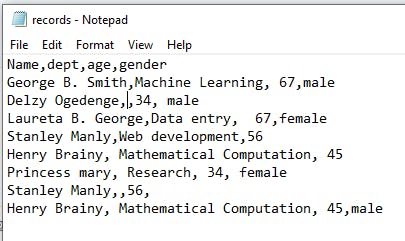
To get the data into jupyter IDE the .read_csv() method will be used. To use the method, we pass the file path as the first argument; there are other arguments that can be passed along, but for now let's work with the defaults.
1 import pandas as pd
2 df=pd.read_csv("records.csv") # Reads in the data. It is saves in the variable 'df'
3 print(df) # displays the data set read in
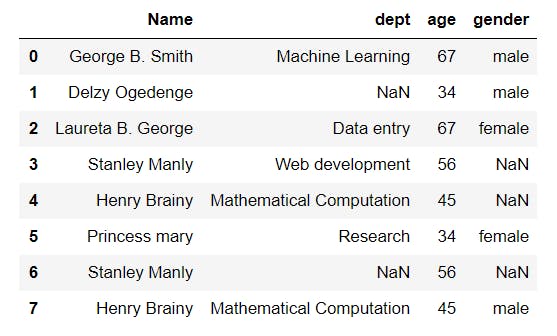
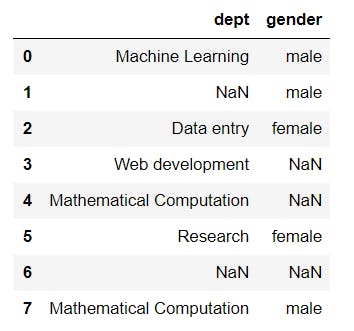
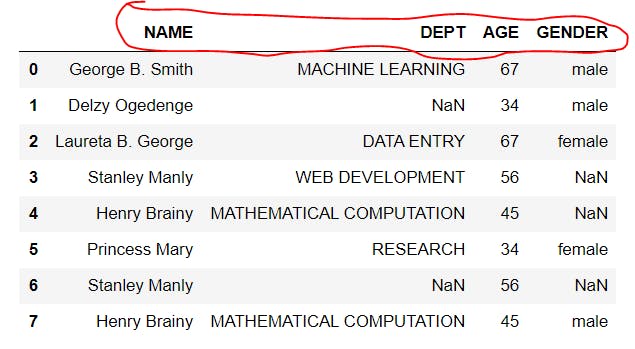
Notice the cells with NaN. These are due to the missing values included in the data set, as shown in the image below
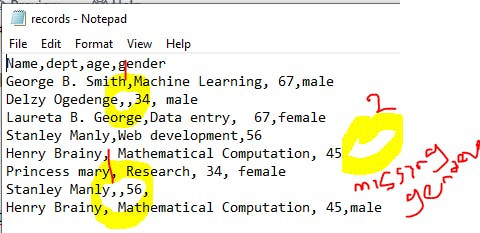
Now, there are a few things we need to take care of in the data set. First, we assume we don't need some information, hence we need to remove them.
Dropping Index/Columns
To drop a column/Index, we use the .drop() method, which takes a list of columns/indices to drop as the first argument
4 df.drop(["Name"])

The above code gives gives an error because by default the method looks for the items in the list on the row, i.e assumes "Name" is an index. To take care of this issue, we need to point it to the column. This is done using the axis parameter as shown below
4 df.drop(["Name"], axis="columns")
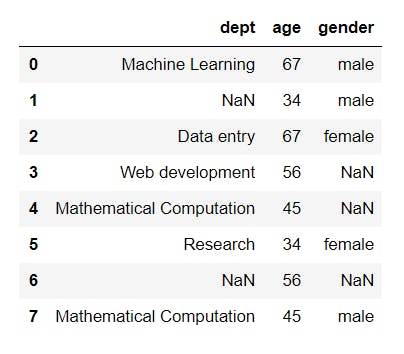 That worked out fine.
That worked out fine.
Now print the content of df and notice that all columns still remains intact. This is because the .drop() method does not modify the DataFrame; it returns a new object. If you want the operation to modify the DataFrame, then you either reassign to the DataFrame or set the inplace parameter to True, as shown below
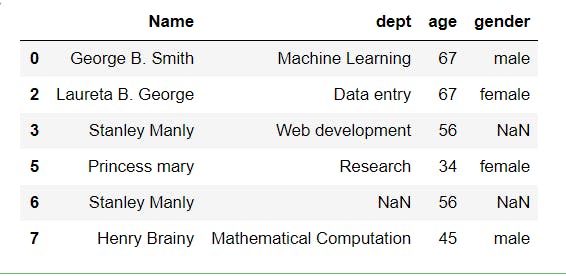
4 df.drop(["Name","age"], axis="columns", inplace=True)
5 print(df)
Notice that we dropped two columns and set the inplace=True.
For the sake of other illustrations we shall be working with the complete data set, i.e the data set with all four columns.
To drop a row or record , we follow the same pattern.
1 df.drop([1,4])# Drops the indices with values of 1 and 4, hence left with [0,2,3,5,6,7]
Notice we didn't use the axis parameter; this is because rows is the default value of this parameter.
Working with string method
One may want to perform some string manipulation on the columns that are of string datatype, however just applying the string method on this is not possible.
For instance, notice that the names in the Name column are not consistent. The names are meant to be title case, i.e the first character of each word being upper case, however this is not the case for most of the cases in the Name and dept columns. Let's fix this
First, let's select and print the columns There are two basic methods that can be used to select a column. One is by using the bracket notation as shown below
1 print(df["Name"])
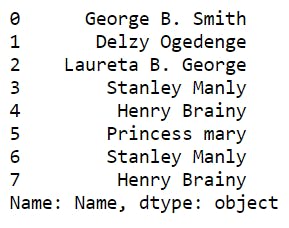
And the other is by the use of the dot notation as shown below
2 print(df.dept)

The bracket notation is better in most cases, especially when the column is not a single word or when one wants to make use of variables instead of the name as a literal.
Ok, let's do some string manipulations. We want to transform the items in the dept column to upper case and we could try the code that follows
3 df.dept.upper()
This gives an error

We can't just access the string methods. This is because we're not dealing directly with a string. To make this operation possible, we need to use the str sub-module, then we can access the string methods as shown below
4 df.dept.str.upper() # accesses the .upper method in the str sub- module

Simple, right? Now if you print df, you would notice that the column remains the same. To make this act stay in place, we need to reassign as shown below
5 df.dept=df.dept.str.upper()
Now, let's use this on the Name column, transforming the names to title case in order to make correction to the name in index 5.
6 df.Name=df.Name.str.title()
7 print(df)
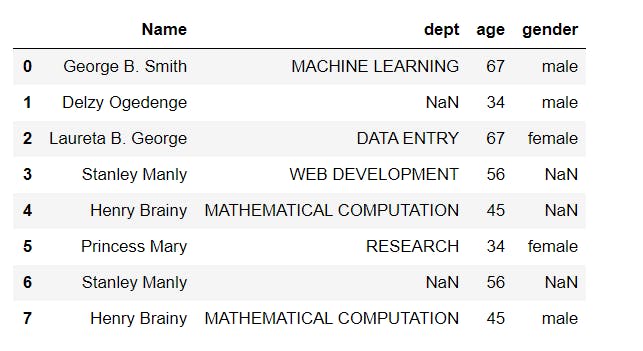
Finally, let's change the column names to upper case
8 df.columns=df.columns.str.upper()
7 print(df)
Conclusion
Once you understand the methods in pandas, you will find out that there are a whole lot of ways of carrying out the same action. Well, we always look for the fastest or the one we can easily remember. In the next post, we shall be considering different ways of handling missing data(data imputation) and how to make selections from a DataFrame. have fun, practicing. Cheers!!
This post is part of a series of blog post on the Pandas library , based on the course Practical Machine Learning Course from The Port Harcourt School of AI (pmlcourse).