




Hello, community!
We recently concluded the problem-solving, beginner-friendly 2-day Learn With Google AI and Crowdsource ExploreML workshop on applied machine learning. We are sorry we could not provide a recording for the workshops due to technical issues, and hence why we are sharing a recap of our sessions and slides in this article.
If you attended the workshop, please endeavour to check your email inbox for additional details.
This recap is divided into two parts;
Day 1: Introduction to Machine Learning. (This article.)
Day 2: Getting Started with Neural Networks and Understanding How Machine Learning Works.
Disclaimer: All slides/images are credited to Google AI and Google Crowdsource facilitator resources. Any image that isn't, will be credited to their rightful owner/author otherwise.
Table of Contents
Recognising What Software Engineering Approach To Consider for Specific Problems.
What is Machine Learning?
We got introduced to Machine Learning and learnt what it is. A broadly accepted perspective is; Machine learning is a specific field of AI where a system learns to find patterns in examples in order to make predictions.
Next, we saw a practical, beginner-friendly example of how ML works with Google's Quickdraw which you can play by clicking here. We discussed how the game works (HINT: pattern recognition), how it was able to recognize your drawings, and how you could program applications like these. You can find the data for building a similar application to Quickdraw here.
Still citing the example of building an application like Quickdraw, we got to learn about the two software engineering approaches you could use in building this application; rule-based methods (your traditional software engineering) and machine learning-based methods.
Rule-Based Approach
You may already be familiar with traditional programming where you start with a goal, write logical rules (your if-else statements), and refine through testing until it works the way you want it to. This is, of course, more than affective for us in building solutions to simply to fairly complex problems (such as sorting a list or displaying an image or webpage if a user requests it).

Credits: Google AI and Google Crowdsource.
Imagine if you tried to describe a carrot the way you just described using traditional programming rules such as those on the right side of the slide. This approach would get very complicated especially if you wanted to account for all of the possible ways one could draw an object. I mean, carrots make look all the same, but they do not all the same exact features (like leaf height and size).
We can start to see some limitations of rule-based systems. They fall short in problems where the inputs are uncertain (vary a lot) and are unpredictable. Enter... Machine Learning-based approach!
Machine Learning-Based Approach
Machine learning is an alternative approach to building software. Instead of programmers creating the rules, a model is trained with examples. Rather than trying to define for the computer what a carrot is and account for all of the possibilities (which is virtually impossible), the computer is given lots of varying examples like you saw in the Quickdraw data and told this is a carrot, this is a carrot, and this is a carrot. This approach results in a more flexible understanding. (Now you can see why machine learning is an artificial intelligence technology?)
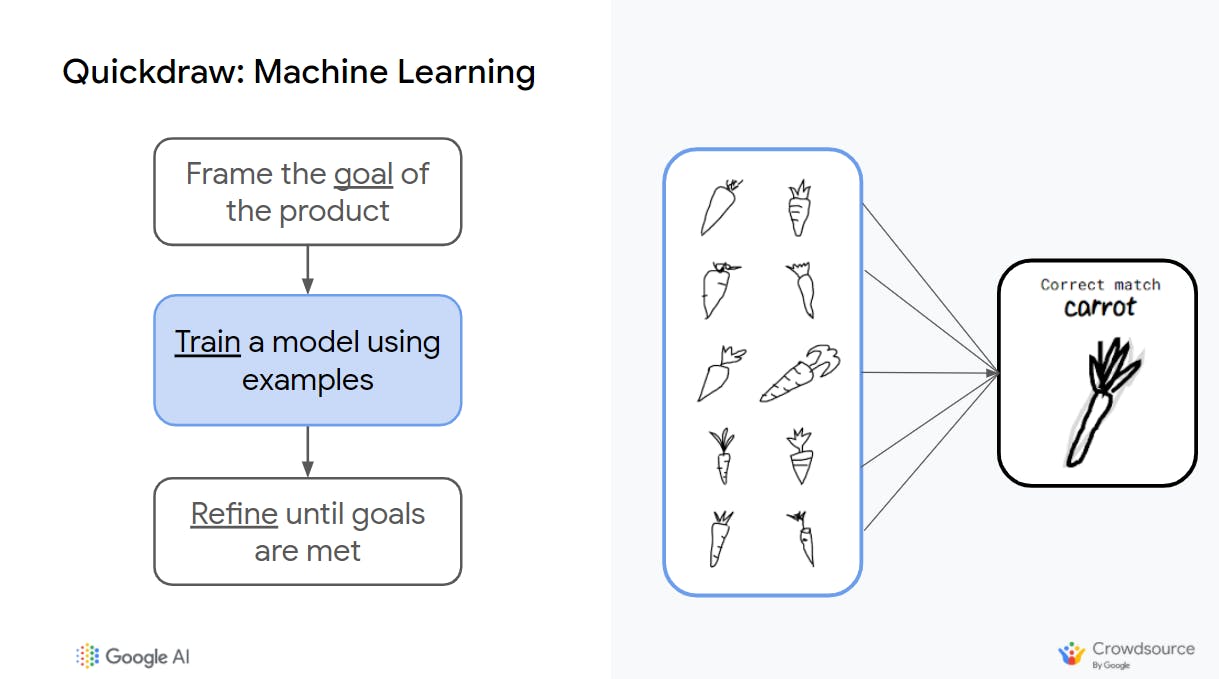
Credits: Google AI and Google Crowdsource.
While this is a revolutionary approach to software engineering, you could also argue that it has some limitations. The machine learning model is only as good as the examples, the data you train it to derive its predictive rules—learning to distinguish between what a carrot is and what it isn't—on. It's essentially GIGO ("garbage-in-garbage-out") as well. For example, if all of the examples are triangle-shaped, it might fail to recognize a rectangular-shaped drawing as a carrot.
The question for you is: What type of tasks do you think would be a good fit for machine learning? (You can answer that and tag us on Twitter @PHCSchoolOfAI using the hashtag #GoogleCrowdsource, #GoogleAI and perhaps adding the article.)
Recognising What Software Engineering Approach To Consider for Specific Problems
In the next section, Mr Phillip showed you some examples of specific problems and the best approach(es) to them;
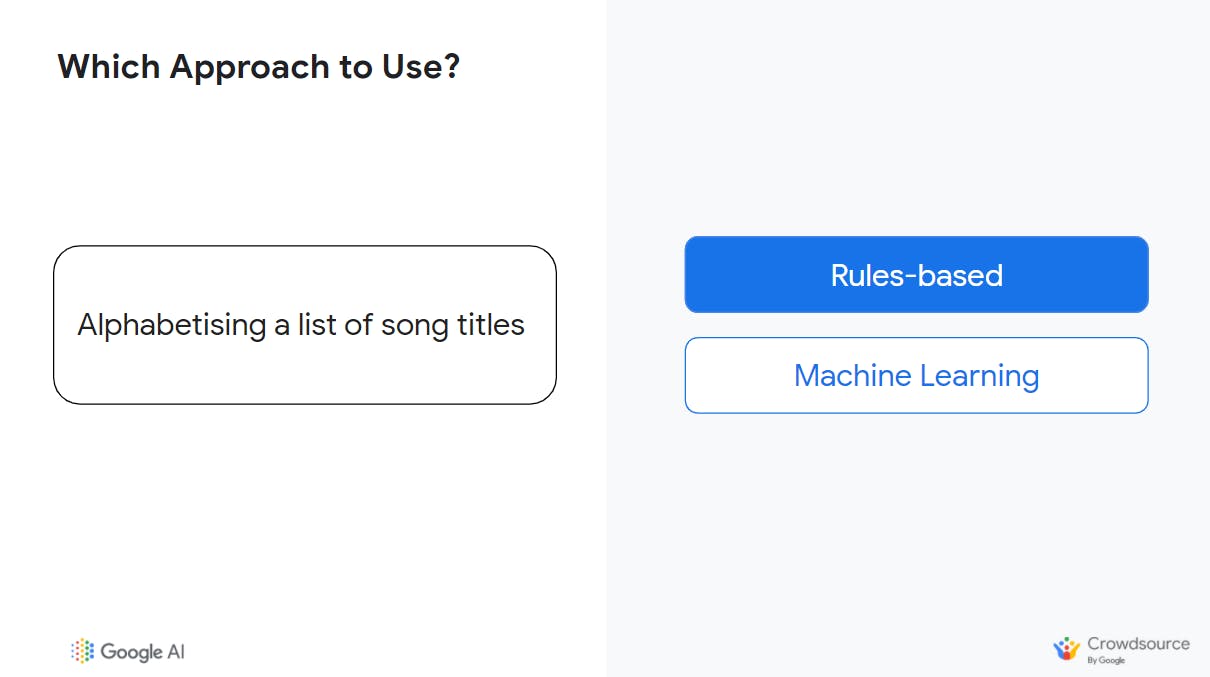
Objective/Goal: Alphabetising a list of song titles.
The above is a rule-based approach because it is a very simple problem with only 1 to a few more ways to approach solving it. There are a fixed number of letters in the alphabet so there are only so many rules one would need to write.
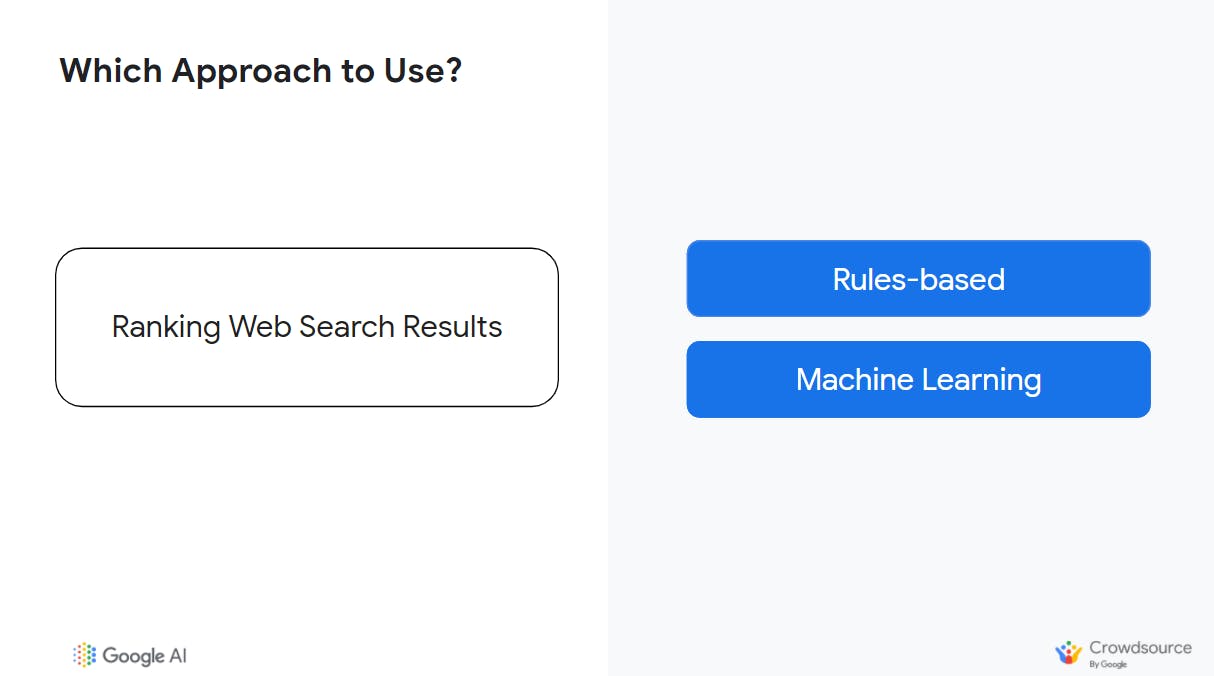
Objective/Goal: Ranking web-search results.
Ah yes, Google's primary domain! Both rules-based and machine learning systems could work well here. The approach you take would depend on your goal. Are you ranking web results based on relevance to my query? You can see that there are various ways you could define "relevance"; hence match that problem complexity with a solution that is machine learning-based.
If the query was news, you might also want to take into account how recently the article was posted. This is a simple problem that can be solved using a rule-based approach. So sure, both approaches combined could work depending on your goal and defined objective.
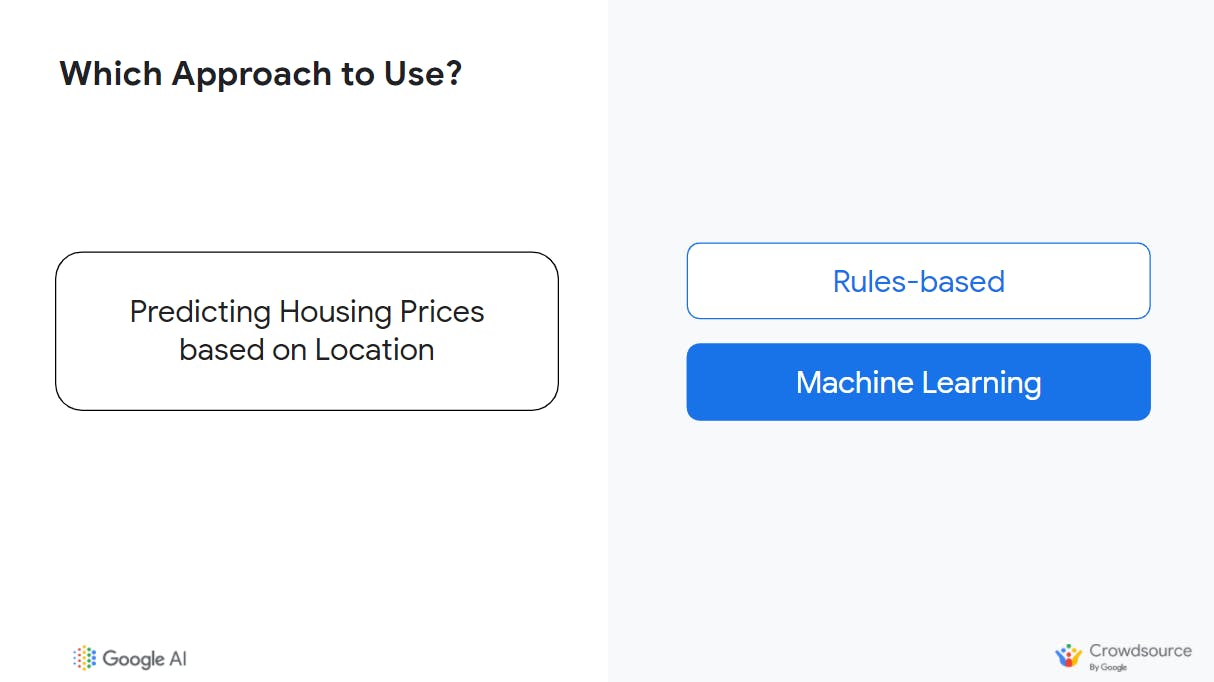
Objective/Goal: Predicting house prices based on a location.
A machine learning-based solution is useful for this objective because there is no perfect formula determining how much a home would cost based on its location, hence making it a complex problem—suitable for machine learning.
There are other factors that could play a part in how much home price costs. These include; the house age, number of rooms, attached or detached garage, comes with a pool or not, and so on. We typically refer to such problem (and solutions thereafter) as "value estimation" with machine learning.
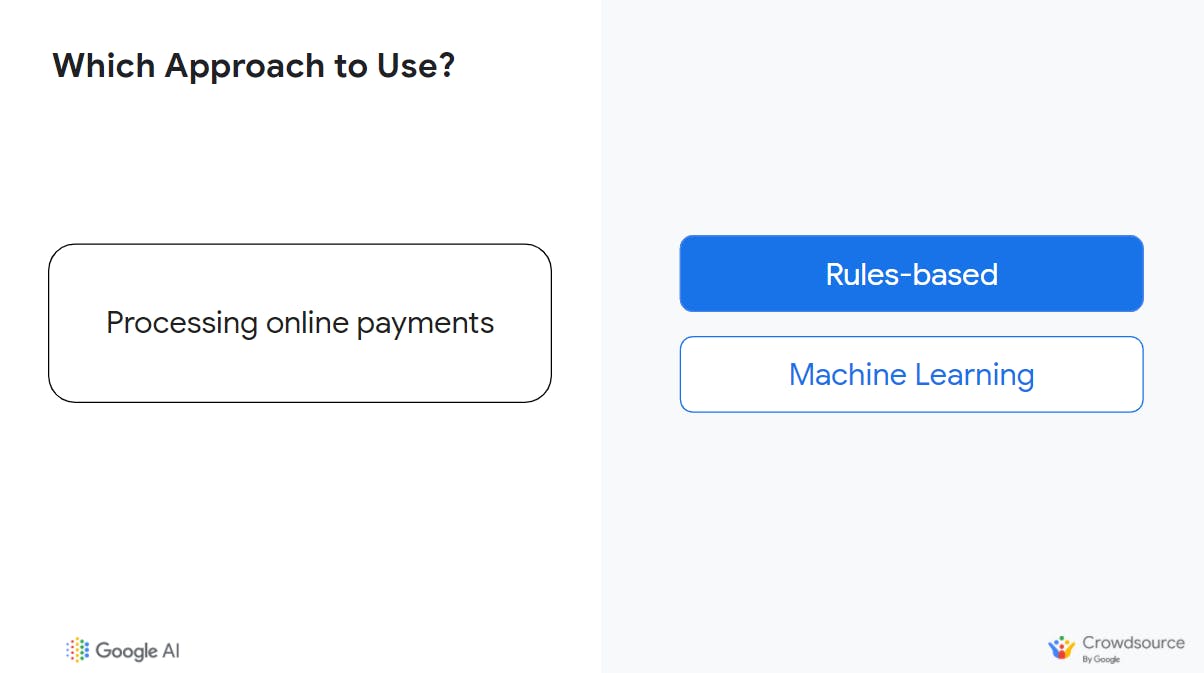
Objective/Goal: Processing online payments.
This depends on what you mean by "processing". In one sense, it could be that whenever our customer wants to make a purchase, we take some certain logical steps in processing the payment for the customer. For example, if Customer X wants to make a purchase --> check customer ID --> if customer account balance > amount for the purchase --> confirm purchase --> else, decline purchase.
Let's take a look at one more objective...
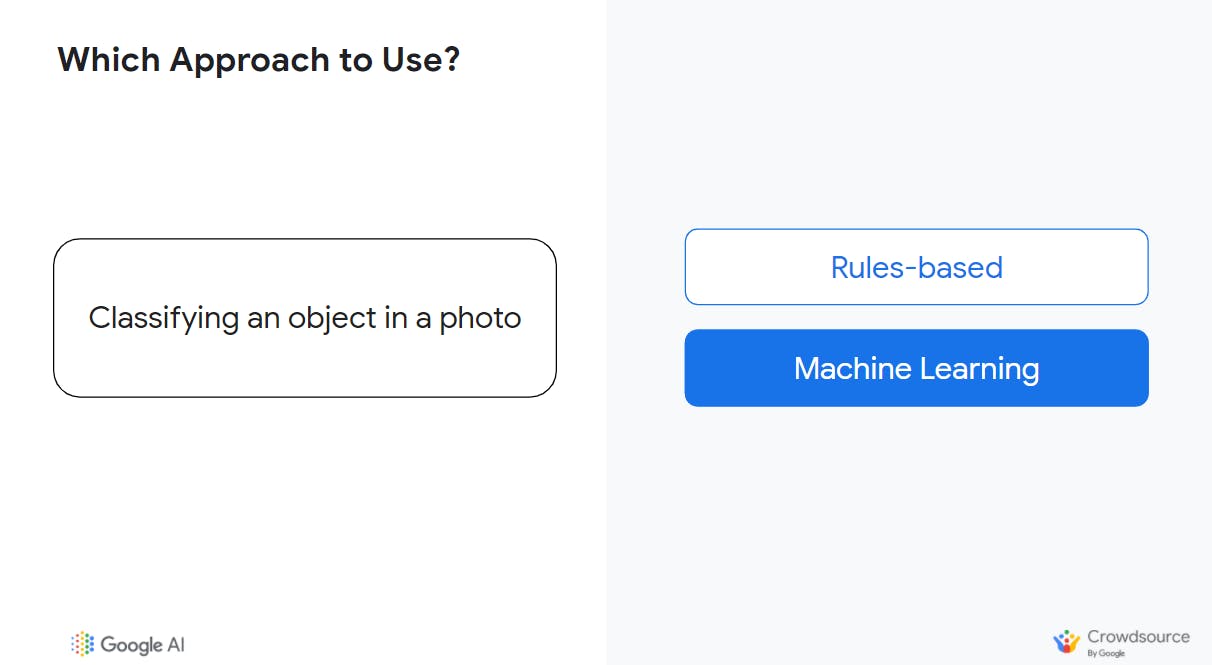
Objective/Goal: Classfying an object in a photo.
I think this is one of the most common applications of machine learning out there today because its complex enough and there is an increasing number of ways we can easily get images of various things objects (such as cars, humans, stop signs, clothing) we want to classify. It is complex because there are too many variables to try and create rules for every situation of recognising objects (such as carrots in an earlier example we saw).
No two photos are alike, so even a photo of a famous landmark (for example, Zuma Rock in Nigeria) could be captured at different angles, times of day/lighting. This would make it much harder to define what an object is in code.
Machine learning is perfect for this because it builds a representation from many examples (data) like this so it can be more flexible and able to handle these (varying) situations.
Recap of Rule-Based vs ML-Based Approaches
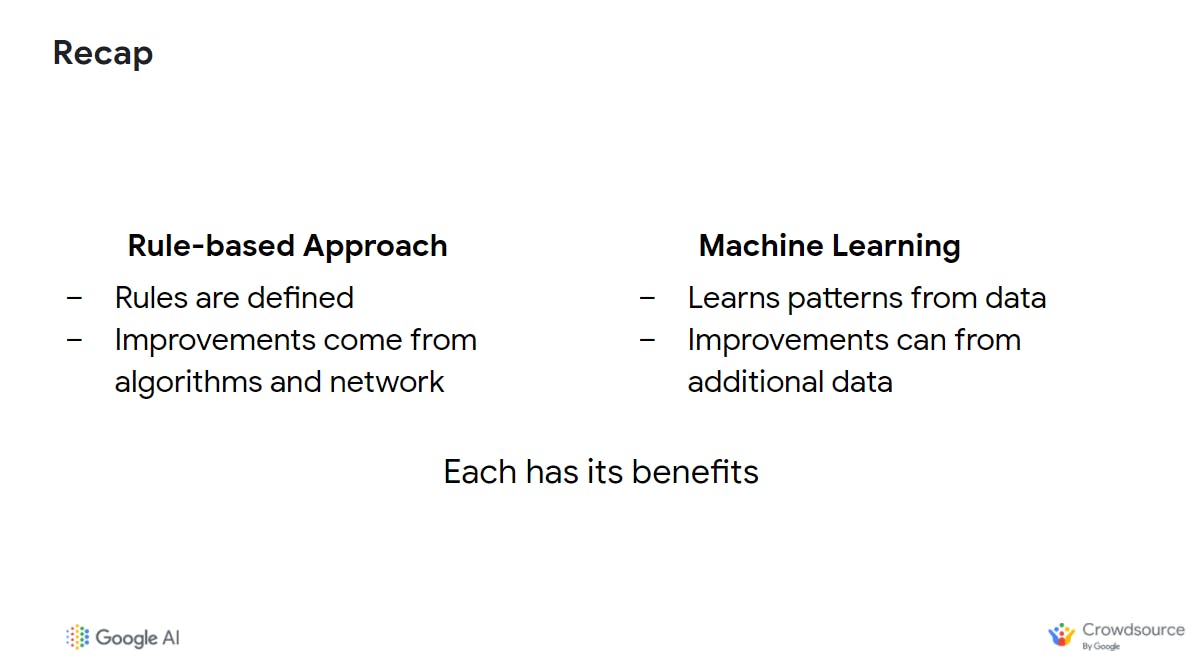
As you can see, ML is perhaps not the defacto solution to all problems, but it is super useful to identify where a rule-based approach will make sense vs machine learning-based approach. You can also find a helpful table below (inspired by my learnings from Janani Ravi);
| Rule-Based Approach | Machine Learning-Based Approach |
| Your defined objective/goal is fairly simple. | Your defined objective/goal is reasonably complex. |
| Inputs and rules for solving the problem do not change frequently; they are mostly static. | The input data changes often and hence the rules to solve the problem should be dynamic enough. |
| Rules for solving the problem are straightforward or in logical steps. | Rules for solving the problem need to change often as data arrives. |
| When you have little to no data to solve the problem and to train a machine learning system. | When you have a large amount of data to solve the problem and to train an ML system to recognize useful patterns and make predictions. |
Going From Idea to Implementation
We tagged this workshop as a "problem-solving" workshop and in fact, why we had to talk about the machine learning process and the challenges surrounding the implementation of an ML solution. In this section, I'll provide an overview of the process as well as important considerations.
You can watch the video below to get a sense of what it takes to implement a machine learning solution.
(Unlisted) YouTube video on implementing ML solutions from ideas.
As you could see from the video, the process of taking your idea and building a workable machine learning solution involves three (3) phases; collect data, create a "model" (fancy word for an ML algorithm that has trained on data), and production (where the end-user—which could be an actual human or another system like another downstream technology—could make use of it).
But before thinking about machine learning, you want to make sure that you understand what your problems or ideas are, and frame them in a way you can decide between solving them with a rule-based approach (if feasible) or a machine learning-based approach. This is a part that people often get wrong.
You'll find a broad overview of the entire machine learning process below;
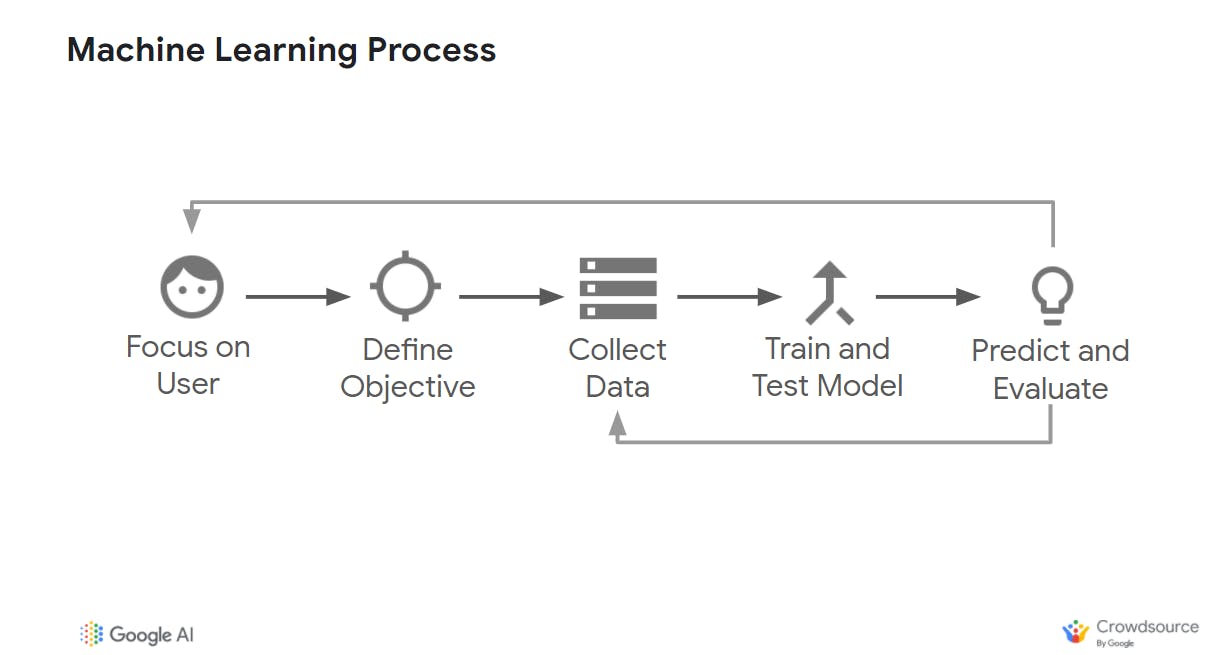
As you can see above, the Machine learning process does not begin with actually building a machine learning solution but on understanding and focusing on the needs of your user and business. If you cannot define the problems your users are facing or problem your business should solve, then there's no point proceeding to the next phase. You'll often have to work with product managers and business stakeholders for this phase. (Try out this course.)
With this in mind, you define an objective so you know how to proceed. This objective has to be framed as a software engineering solution (if it is, in fact, a software engineering solution).
Examples could include:
i. Predict which friends a user is likely to share a photo with.
ii. Suggest the user should eat in a new city based on the restaurants they have visited in the past.
Once you have defined the objective/goal, you then try to understand what approach is useful; rule-based or machine learning-based approach.
The goals and objectives you define should articulate success metrics as well. Ensure you understand what level of performance is acceptable for you to consider the project or solution as successful or useful.
You would also want to categorize the problem into; a supervised learning, unsupervised learning, reinforcement learning, recommendation learning problem, or even self-supervised learning problem.
No surprises here as machine learning models learn from data—and large amounts of them! So it is essential to find a large existing source of data that is relevant to your problem. Make sure you get the data in quality and quantity. This means not just getting them in large quantity, but also ensuring the dataset is representative of all the likely scenarios your model will encounter while in effect.
Experts say, collecting, cleaning, exploring, and other data processes tend to be the longest but most critical part of the process. Remember, your machine learning solution is only as good as the data it trained on so ensure you spend the necessary time here preparing a quality dataset for your machine learning system/algorithm.
Train your machine learning algorithm/system (could be a system like Google AutoML), validate its results, and then test it to see if it meets your success criteria.
If it meets your success criteria and other factors (such as system biases and user privacy) have been considered, you can now deploy your solution to end-users. But it doesn't stop there! You'll need to monitor and evaluate the solution often to make sure it works as expected, it is not deteriorating and performing below the set expectations, and so on.
The arrow pointing back from prediction to data shows the iterative nature of ML. You will need to refine your model and perhaps your data collection and processing based on the feedback until it is achieving the results you are looking for.
Bias in Machine Learning
We have a thorough discussion on how to identify biases in machine learning systems, and participants were gracious enough to give their perspective on how to combat bias in ML systems. We noted that biases could happen anywhere in the machine learning process. From understanding the problem you are trying to solve, to framing the objective, and more prominently collecting and preparing datasets.
You can watch the helpful video below to learn more;
YouTube video on Machine Learning and Human Bias.
After watching the video, here are some questions you may want to interact with;
When someone describes to you a new application of machine learning, what questions would you ask them based on this video?
What approaches could a software development team take to mitigate bias in their machine learning system?
Privacy in Machine Learning
Privacy of your users' data and sensitive information is very crucial when you are trying to implement a machine learning solution. The video below gives you an insight into privacy in machine learning, and some steps on making sure you are taking the right steps in protecting your end-users while implementing an ML solution to solve their problem—remember, it's all about focusing on what's best for your end-user!
YouTube Video on ML privacy.
You can take a short reading break (perhaps some 5 minutes)—but make sure you come back to finish this. 🤗
What Can ML Do?
It is crucial you understand some real-world problems that machine learning can be suitable for, and we discussed some of them during the workshop.
But before moving on to seeing examples of problems ML solutions can.. well... solve, let's clarify some terms.
AI vs ML vs DL
In news articles and discussions, it's common to hear artificial intelligence (AI), machine learning (ML), and deep learning (DL) used interchangeably but there are distinctions between them.

Diagram source: Google (author: ostrowskid@)
AI (Artificial Intelligence)
Artificial Intelligence is defined as any technology which appears to do something smart.
This can be anything from programmed software to deep learning models which mimic human intelligence
ML (Machine Learning)
Machine learning is a specific kind of artificial intelligence but rather than a rule-based approach, the system learns how to do something from rather than being explicitly told what to do.
DL (Deep Learning)
Deep learning is a specific type of machine learning using a technique known as a neural network which connects multiple models together to solve even more complex types of problems.
Deep Learning, similar to other ML models, learns via examples. It's unique because it connects models to other models in layers in order to handle more complex types of data like as images.
Simplified Overview of ML
That brings us to this very simplified overview of the history of machine learning. You can find more detailed timelines on Wikipedia etc but here's the main takeaway.
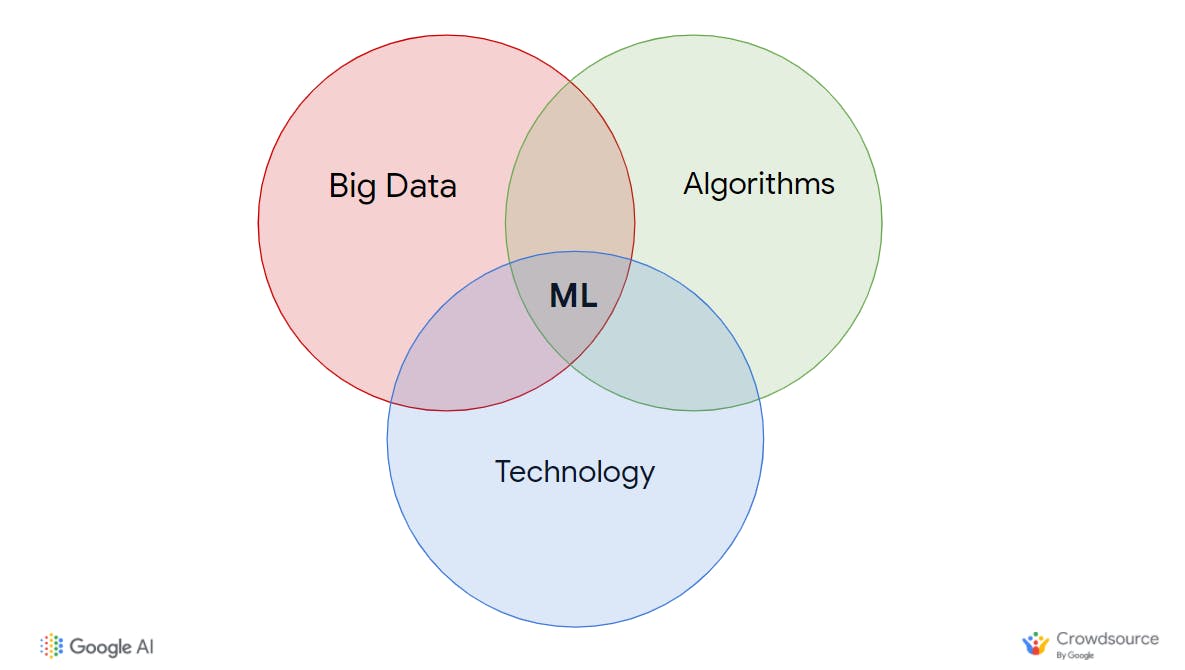
The key algorithms powering machine learning were formulated even as much as centuries ago. They come from disciplines like statistics, mathematics, biology, physics.
For the last few decades, sufficiently large amounts of data were collected to train models but they were low quality and expensive to train. Lack of progress and prospects led to an "AI Winter" where ML was considered a waste of time.
In the last few decades, the availability of relatively cheap and fast computing power has enabled the complex calculations across large sets of data (big data) necessary to train highly accurate models.
If you are interested in learning more, you can visit here and here.
Types of Machine Learning Solutions
There are some common and successful types of machine learning solutions to well-defined problems.
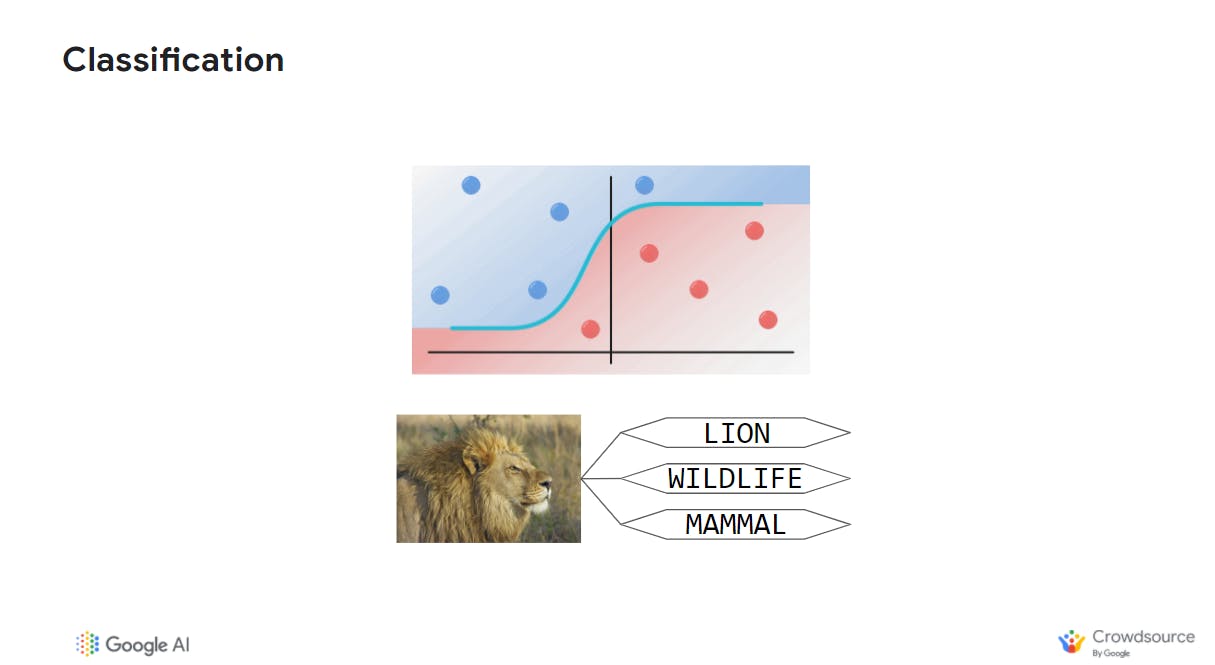
Classification diagram source: Google (author: ostrowskid@). Lion image from Pixabay. Free for commercial use no attribution required.
The system determines which class or a category an input image belongs to. The output can be a label (this is a lion) and a percentage of confidence (97% confident).
For example, if the classifier was trained to identify whether or not an image was of a lion it might output "Yes" or "No", however, if it was more generically an animal classifier the output could be "lion" or "tiger".
Classification systems depend on a threshold set by human developers so the system can distinguish between cases that might be less clear. If you built an email spam classifier it would be necessary to fine-tune the threshold so your system didn't incorrectly label an email as spam when it was genuine.
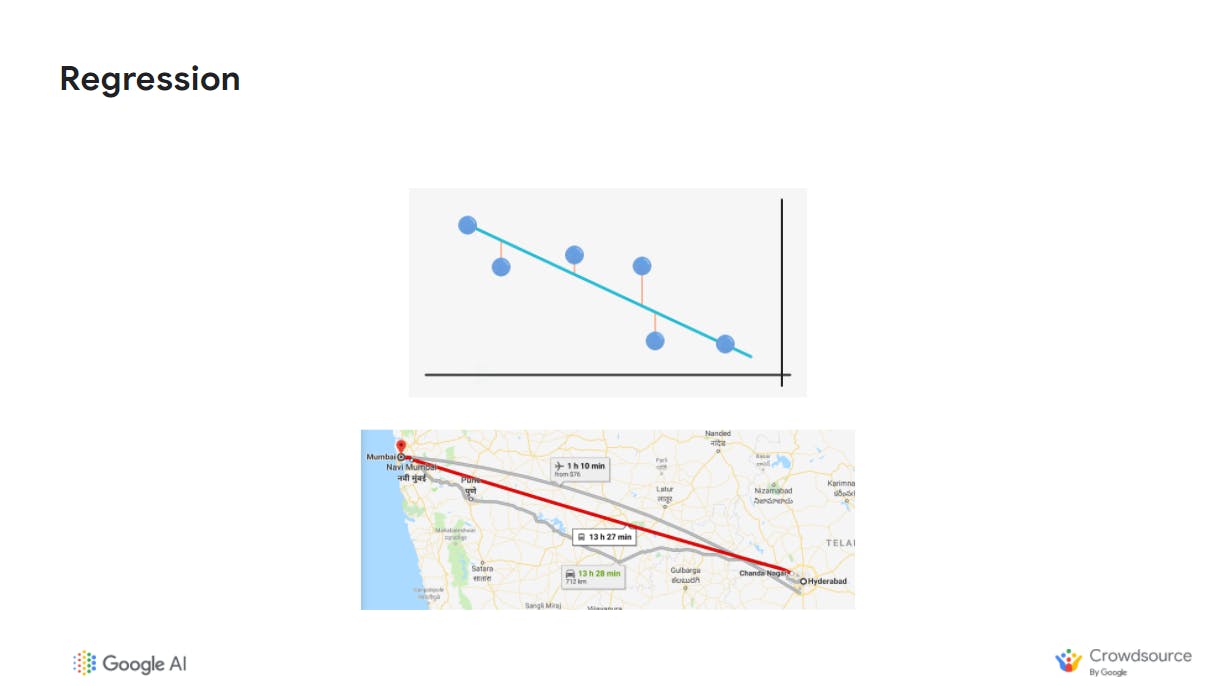
Regression systems output a number for example how long it will take to drive from point A to point B or the likelihood that someone will click on an ad.
Regression systems can be as simple as drawing a line as you see above or more complex models depending on multiple variables (features of your data like location, traffic in an area, how long people have spent going from point A to point B in the past).
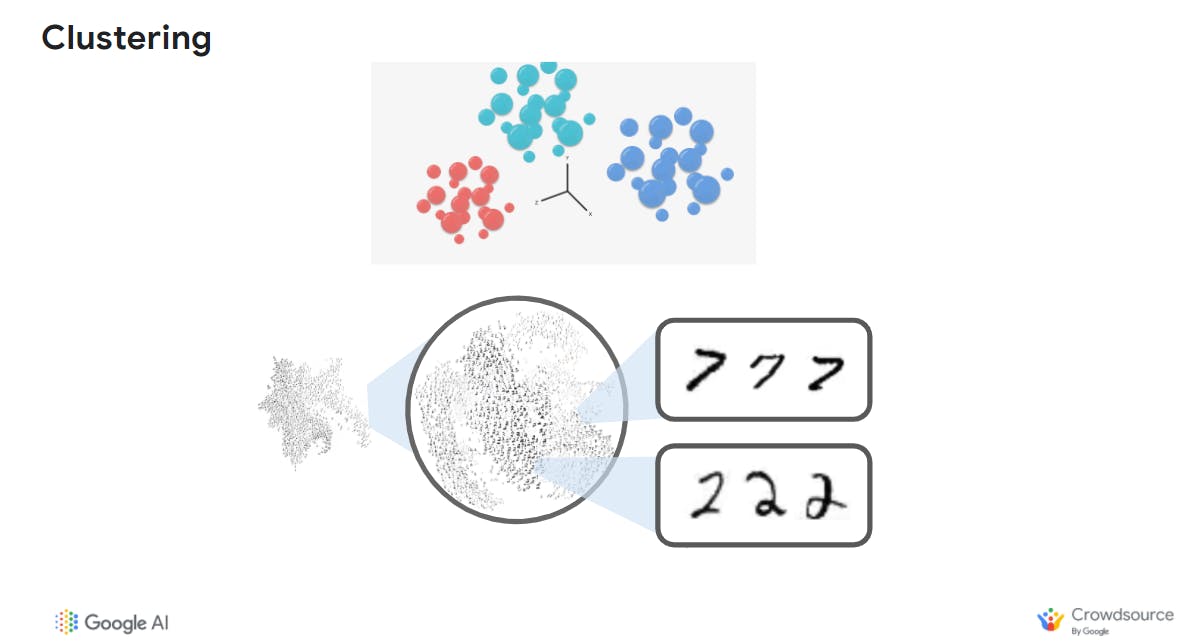
Clustering diagram source: Google | Screenshots from the embedding projector.
This application determining how closely related items are to one another and then creates "clusters" to segment closely related items with each other based on the features learned from the data.
In this image above, the data of hand-drawn images are moved into clusters of the same number (1s with 1s, 2s with 2s etc). Even within clusters of the same number, the images are further clustered by those which are similar in shape. For example, some 2s and 7s may look similar. This could also happen with words that have closely-related spellings.
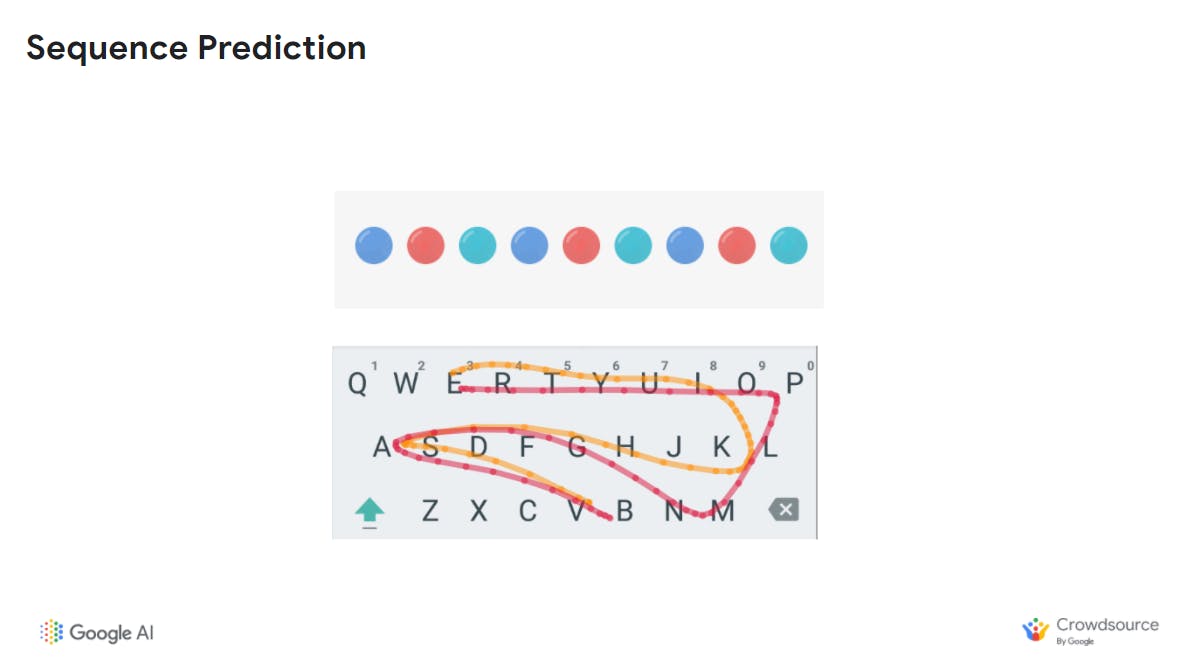
Sequence diagram source: Google | Keyboard source: Google
In order to assist users, it can be helpful to predict what they might do next. This could be a prediction of the next keyboard key a user will select as you see in the screenshot. This could be used to propose a spelling correction or suggest replies to a text message. It could also include predicting the next word a user might likely want to use, or even an entire sentence.
Other examples of sequence prediction could include the next video a user might want to watch (as in ahem YouTube and Netflix) or the next stop on a vacation (as in Google Maps).

Style Transfer or Generation involves training a model on one set of data and then applying that model to something completely different. It could be as seen in this example remaking photographs to look like another piece of art or converting a voice from male to female or even another language.
An example as seen in the image above could be generating a new style of art on a photo, based on an "image style" the model trained on. Voice conversion is taking the voice of one speaker, equivalent to the “style” in image style transfer, and using that voice to say the speech content from another speaker, equivalent to the “content” in image style transfer (source here). See the image below;

Source: Andrew Szot's blog post here.
You can learn about the technical details on how style transfer works here.
Some Machine Learning-Based Problems and Their Solutions
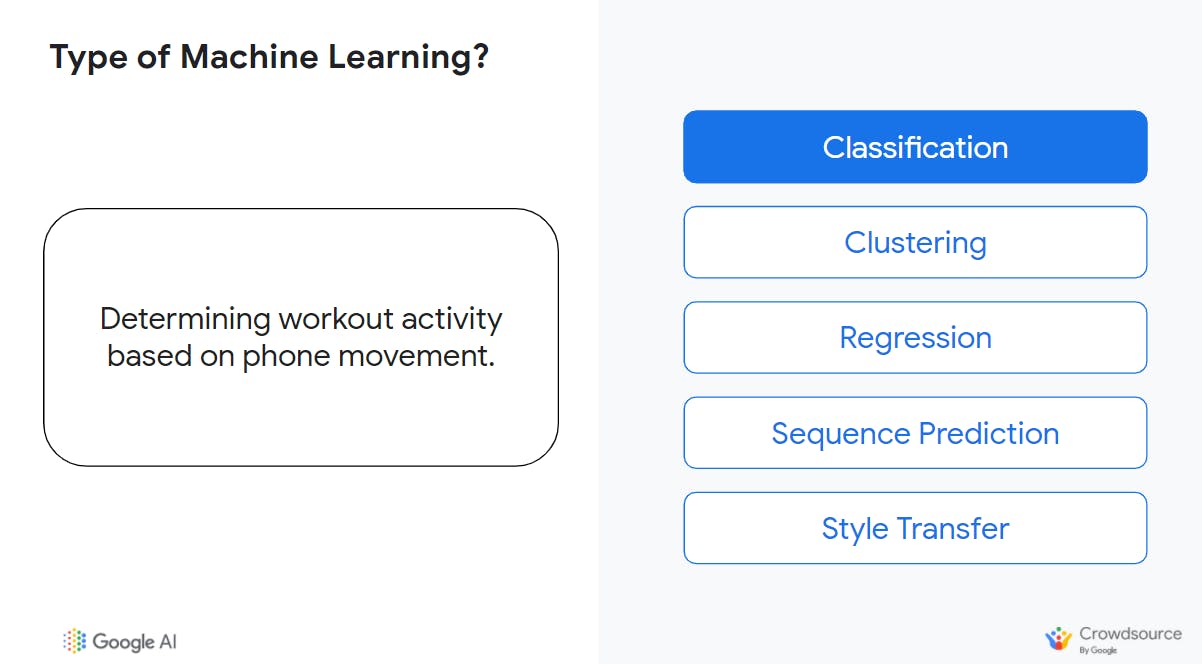
When we asked participants of the workshop what the right solution to this problem could be, most selected sequence prediction (and for a good reason as well) but the goal here is to output discrete labels such as walking, running, jumping—which makes this task a good fit for classification.
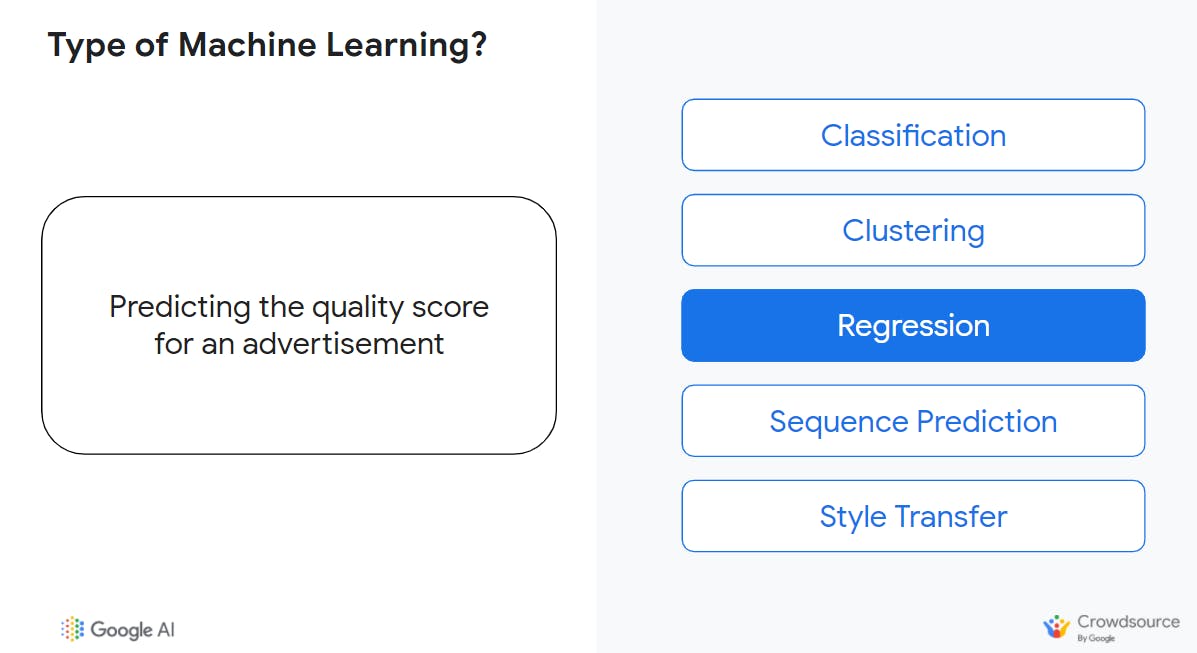
The output of the machine learning system is a continuous numerical score such as 3 out of 10 or 97.2%. This score would probably be based on numerous features such as the ads the user clicked in the past, the search history of the user (such as keywords) and how frequently they searched them, and so on.
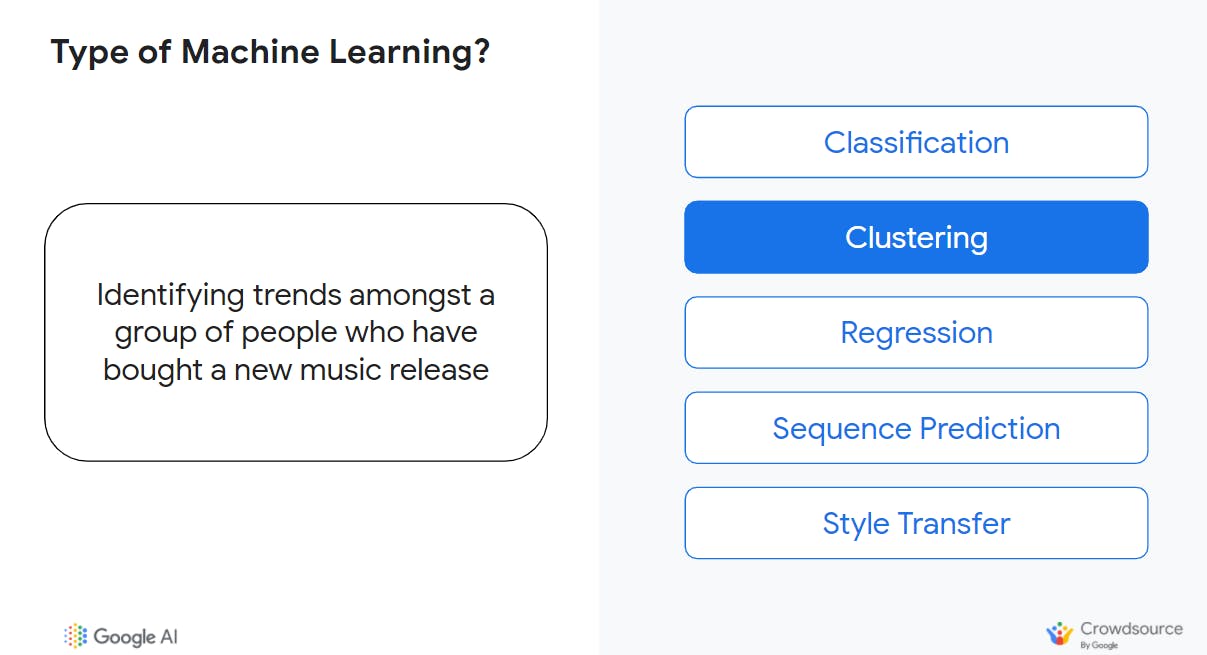
The goal for this problem is less about making a specific prediction (like the sequence prediction example earlier) but looking for similarities and finding clusters/trends/groupings based on something these group of people in common—for example, music genres they have listened to in the past.
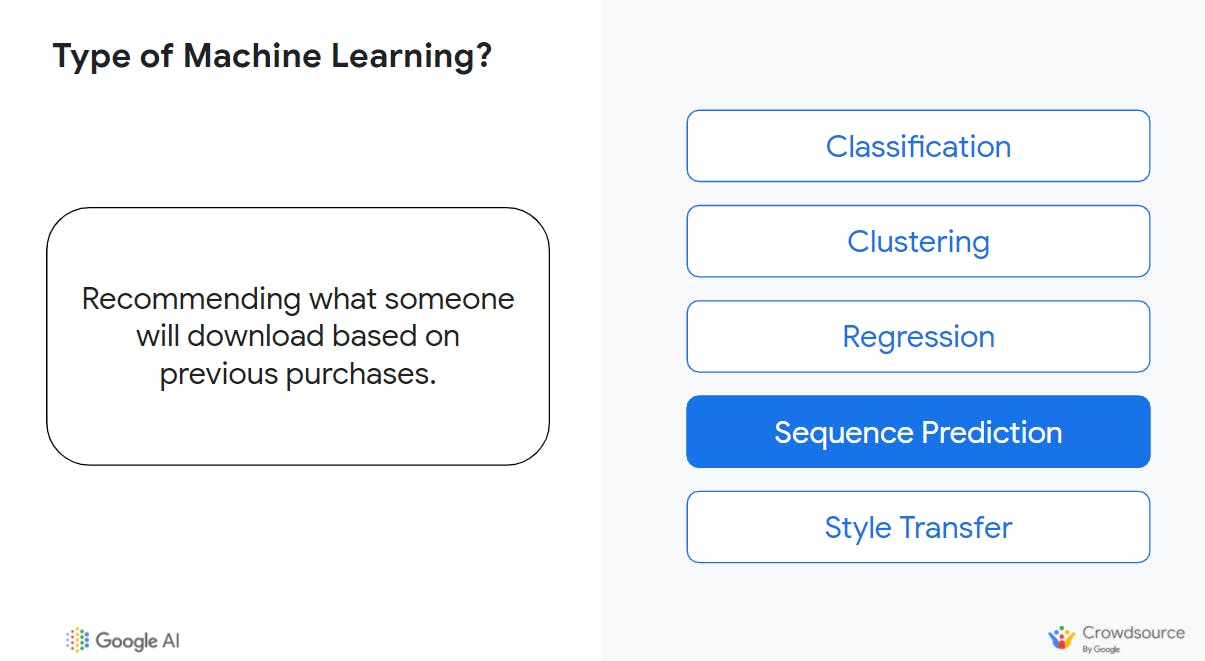
While all examples of machine learning involve previous examples, this is an example of predicting the next thing a person will do based on previous/similar sequences the model has learned from.
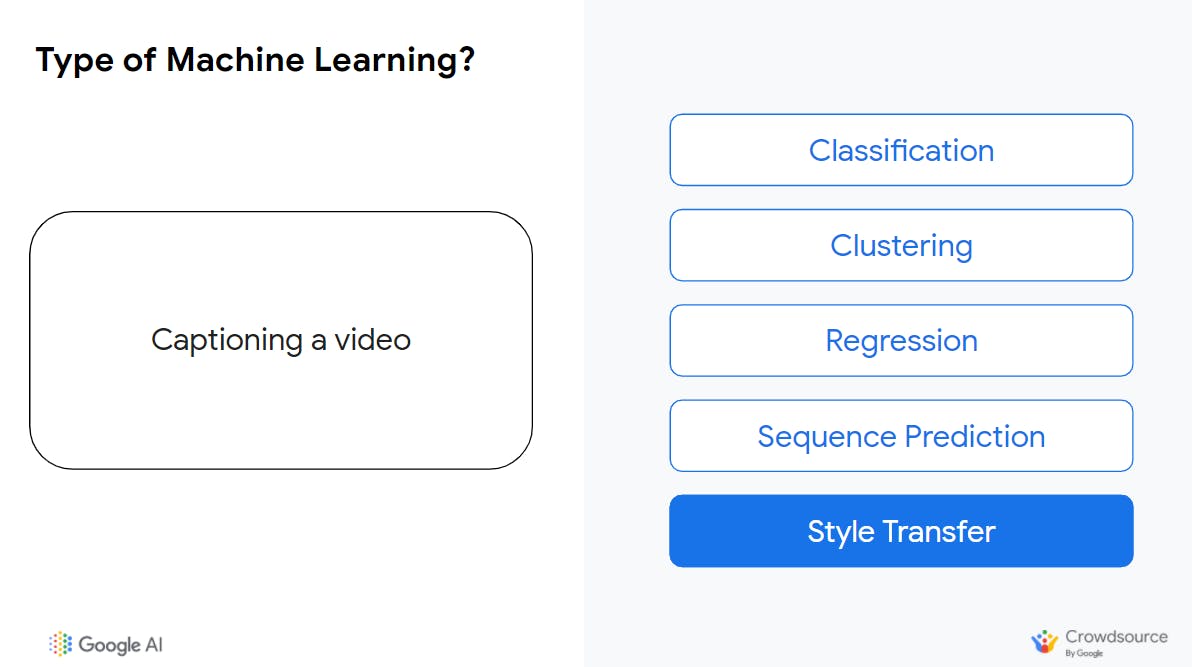
When the type of data generated by the system is different than the input data, this is an example of a style transfer.
In this example the input data: video/image frames are translated into text describing what is depicted in the image. For example, a model could output the caption an image; "People taking photos at Zuma Rock" or a video; "A bird is laying a nest".
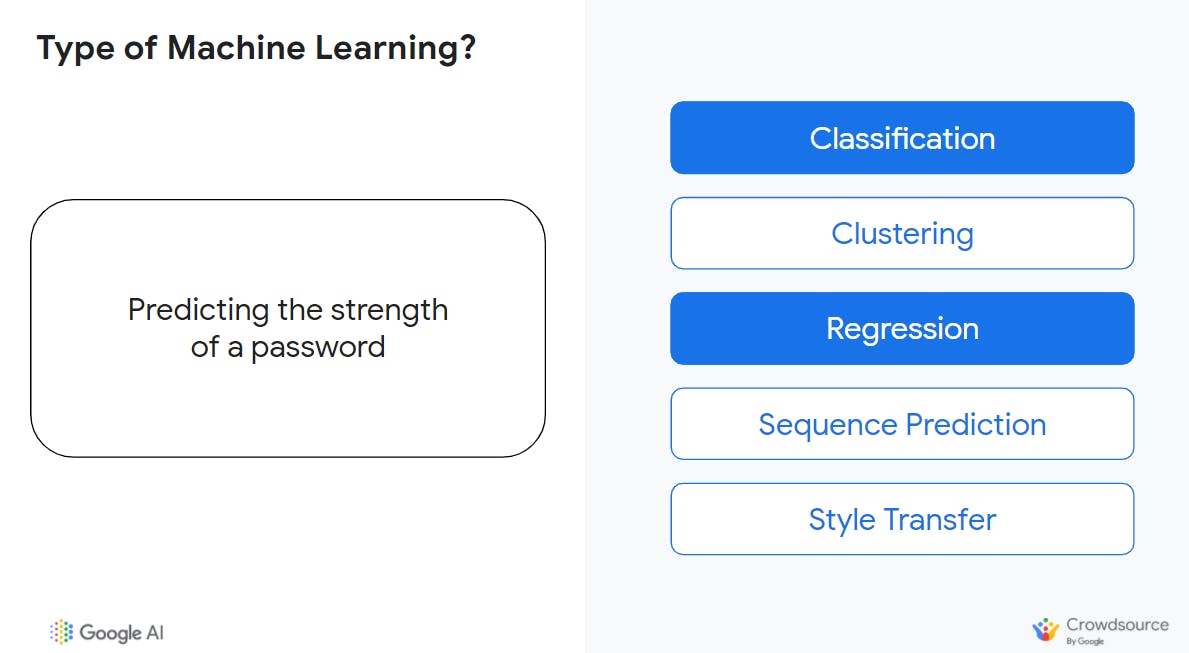
This is an application that can combine two different solutions (such as classification and regression).
In this example;
When the output of a machine learning system is a continuous number such as "Your password is 50% stronger than others" it is a regression problem.
However, your users might prefer you take that output and simply classify the output as Weak or Strong—a classification problem.
Review and Next Steps
That's it! We have been able to give you a glimpse of what happened on the first day of the workshop. In this article, you must have learnt;
What machine learning is,
The good sides (usefulness) and ugly sides (limitations) of rule-based and machine learning-based approaches including some ways to identify when to use them.
How to go from your basic idea of solving a problem to the process of implementing machine learning solutions.
The need to be aware of bias and ethics in machine learning, as well as machine learning privacy.
Types of machine learning applications or solutions.
You can find the post for day 2 of the workshop here.
Next steps? We urge you to join our AI and data learning community by clicking here.
Interested in our another virtual event from our community? We have just the right event to round up a crazy year.

Register using: bit.ly/cr-ads-20
You can share this opportunity with others as well by tweeting or sharing the message below on your social media feed.
2020 has been a wild year for most data scientists! Join us @PHCSchoolOfAI as we end the year with a career recess virtual event, taking the much-needed break from work to interact with other data scientists and learn from the practical experiences of others: bit.ly/cr-ads-20
Did you enjoy the article? Did you find it useful? Send us a comment below and react to it so others can easily find the article as well.
Or...
Did we miss anything? Do you have any feedback? Did you spot any errors? Are you facing any challenges with the links anchored or other details? Please let us know in the comments below.