




A workflow can be defined as a series of steps that need to be completed sequentially in order to effectively get a job done. In our case, a standard Machine Learning (ML) workflow is a series of steps that need to be completed sequentially in order to effectively solve Machine Learning problems.
Practitioners and experts in the industry strongly recommended that a standard workflow should be followed when working on ML projects from start to end. This is because it'll help you to: timely identify projects that won't go anywhere, make better decisions in consideration of how they will affect future steps, measure the solution performance, and easily go back to a previous phase to optimize for better performance of the entire solution.
In this article, I'll introduce you to the steps involved for a standard ML workflow, and how to apply them to a real-life project.
Let's get started.
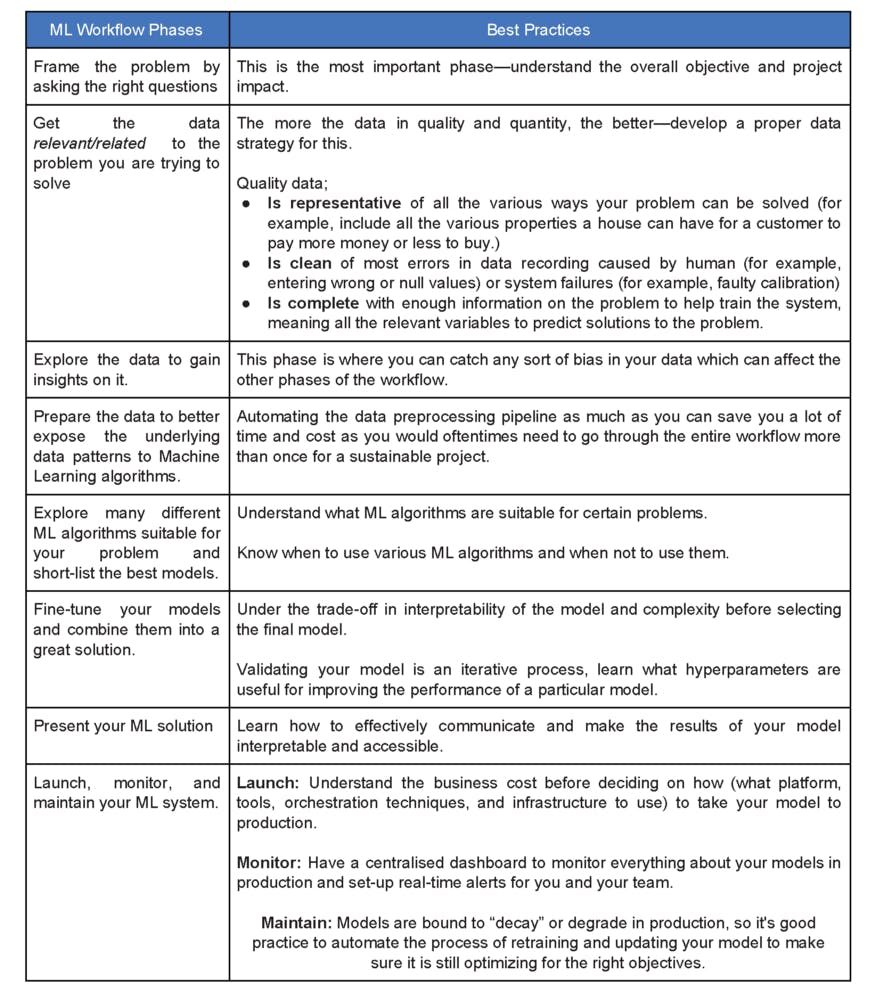 Source: PHCSchoolofAI, based on Aurelien Geron's book Phases of ML Workflow
Standard ML Workflow Checklist
Source: PHCSchoolofAI, based on Aurelien Geron's book Phases of ML Workflow
Standard ML Workflow Checklist
The image above is a summary of the steps involved in a standard ML workflow. As you can see, the standard ML workflow can be summarized into 8 steps. To understand each individual step, let us consider a fictitious real-life business problem and see how this workflow can be applied to it.
Problem Description:
The sales representative of a construction aggregate company has been facing difficulties meeting his sales targets which he believes is because of complaints from clients about inconsistencies in the product quality. From his meeting with the plant supervisor, he found out that the production plant had undergone an upgrade in the last quarter and that raw materials normally go through testing before production. The plant supervisor couldn't see any obvious reason for the inconsistencies but to the sales representative, the time of the upgrade coincided with when the complaints began.
The meeting didn't answer any questions for the sales rep. After doing some more research and interacting with his network, he found out that the machines had data records, so he inquired with the manager of the analytics department for a way forward. The analytics manager informed him of the availability of data that could help them detect the inconsistency in concrete compressive strength through a robust model. Now, the sales rep needs to find out the factors that influence the concrete compressive strength so he can strategize and present his findings to the management.
As an ML engineer whose job it is to build an end-to-end ML project that solves this problem, how can you apply the standard workflow to this problem?
1. Frame the Problem

The first step of the ML workflow gives us the opportunity to properly understand the project we are going into. This first step helps us come to a conclusion of whether the project is feasible and if it's worth carrying out. We need to first answer questions like:
- What is the aim of our solution approach?
- Can ML be used to achieve this aim?
- Why do we even need to predict concrete compressive strength?
Here, the aim is to resolve the problem of product quality inconsistency to improve sales. Predicting the concrete compressive stress and determining the factors influencing it, will help us achieve this aim. So yes, ML can solve the problem.
There are other questions that should be asked in this phase, you can find some of those important questions here .
2. Get Relevant Data

The next step after identifying the focus of the problem and feasibility of a viable solution is to gather data. In this phase, you need to:
- Determine what type of data you need and how much of it you need.
- Find data sources and confirm its legal obligations.
- Get the data and determine its size and type.
- Divide data into test sets and training sets
This phase should be carried out with the help of the project subject domain expert. It is important to ensure data fairness at this stage and make an effort to automate the process so that adding more data in the future will be seamless.
For the concrete compressive strength problem being addressed here, our data source can be found here.
3. Exploratory Data Analysis

After gathering and sorting data, the next step is to draw insights by exploring the data. In this phase, you need to:
- Study the attributes of your data and characteristics.
- Visualize and understand the data correlation.
- Document everything learned from data exploration.
It's better to carry out this phase with the help of a domain expert, which can save you the stress of taking the wrong approach or using the wrong attributes for your model building.
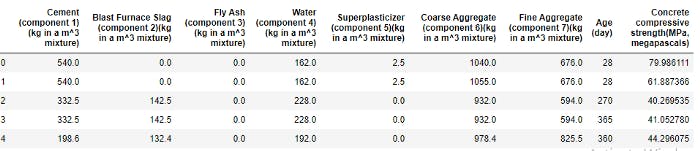
Here are the first 5 instances of the data set we are working with
Also, here is a heat map showing our data correlation.
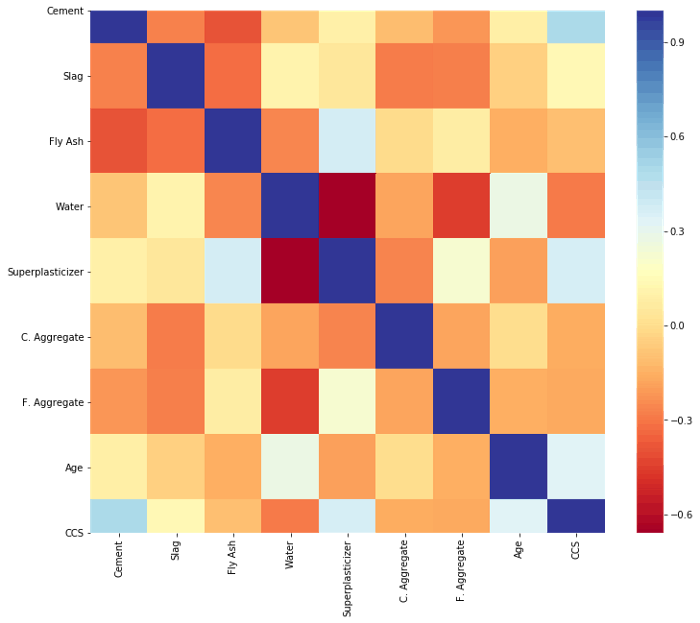
There are many more things you can do during data exploration.
4. Prepare the Data

After data analysis, the next step is to prepare and transform the data so the ML model can be built to better understand the underlying patterns. It will be in your best interest to automate this process so you can easily prepare test sets and fresh data sets or instances whenever you get them. This will help you apply the same preprocessing to any other projects you have to work on.
For our example, I tried different methods of scaling and transformation and decided that the model performed better without transformation. Here's a link to my Github repo, so you can see practically how I have applied the methodology in this article.
5. Iterate over Different Algorithms

The next step after preparing your data is to explore different algorithms that may be suitable for your data set.
From the description of the data set that we're working with, you'll see that the attributes have a non-linear relationship. I deduced this in the preprocessing stage, so in picking algorithms to work with, I gravitated towards more non-linear models.
Again, try to automate this process as it'll help you train your model faster. After evaluating the model performances, you can shortlist the top-performing models to optimize their performance. Pay attention to the variables significant for each model and also the type of errors they make so you know the best candidates in case you decide to build an ensemble model.
You can always go back to any of the earlier phases, to better preprocess and understand attribute relationships.
6. Fine-tune your Models

It's finally time to fine-tune your modulation hyper-parameters and create an ensemble model for better performance. In this phase, you need to keep in mind the trade-off of model complexity and interpretability. For our example project, after fine-tuning, I settled for the Decision Tree Regressor model because it didn't overfit and it was also easier to illustrate the feature importance for the sales rep to see.
7. Present Your Solution

Now, it's time to convert our model into a format that is interpretable and understandable by a non-ML or data science professional.
Let's say I use a PowerPoint presentation of charts and graphs to show the sales representative the attributes that affect the concrete strength more than others, I would then have made it possible for him to communicate the findings with management to effect the required changes.
Here's a representation of the level of importance of the features in predicting the concrete compressive strength as stated in the problem overview, you can see the 3 key features that influence this prediction.
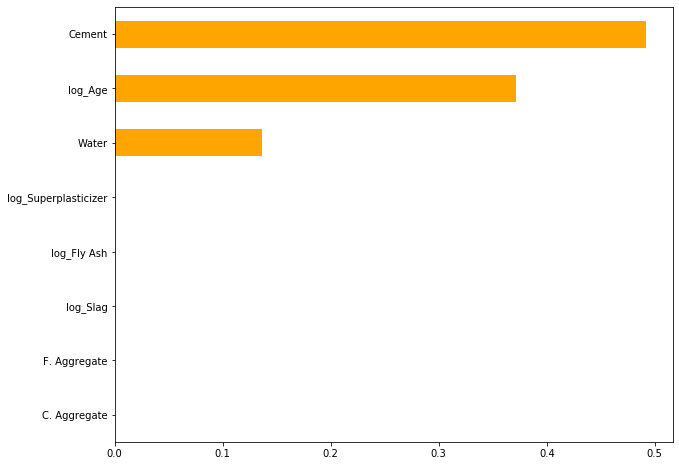
8. Launch and Monitor

Next, it's time to launch your ML solution into production. You can't stop there though, ML systems rot with more data, so you need to regularly monitor your model and, if needed, retrain the model to ensure good performance, even as the data grows.
When deciding how to take your model to production, you need to consider business cost and the user type. For our fictitious problem, what strategy or platform would you use? I'd love to hear what you think in the comment section.
Here's a Github repo of my solution to the example problem.
Conclusion
In this article, we covered the importance of using standard Machine Learning workflow for ML projects, how it can make solving ML problems smooth and bring out the best solutions. I'd like to stress that it's important to perform a needs analysis and ask the relevant questions before ever jumping into solving any problem with ML. This way you won't put in all that work only to realize that it doesn't solve any problem.